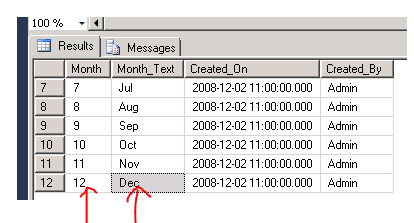
November 21, 2013
How to remove last character in the string , 3 smart ways to handle it
1)
declare @string varchar(100)='ab,cd,ef,'
set @string= reverse (stuff(reverse(@string), 1, 1, ''))
print @string
2) declare @string varchar(100)='ab,cd,ef,'
set @string=
SUBSTRING(@string,1,LEN(ISNULL(@string,''))-1);
print @string
3) declare @string varchar(100)='ab,cd,ef,'
set @VARDAYTAS= LEFT(@VARDAYTAS,nullif(LEN(@VARDAYTAS)-1,-1))
print @string
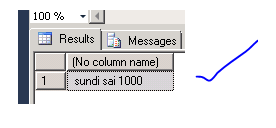
o/p
ab,cd,ef