
December 26, 2013
Grouping,Grouping Set,Grouping_Id how interesting it is
create table #temp1
(
id int,
year1 int,
count1 int
)
--drop table
#temp1
insert into #temp1 values (1,2001,200)
insert into #temp1 values (1,2001,500)
insert into #temp1 values (1,2001,300)
insert into #temp1 values (1,2002,500)
insert into #temp1 values (1,2002,300)
insert into #temp1 values (1,2003,500)
insert into #temp1 values (1,2003,300)
insert into #temp1 values (2,2001,200)
insert into #temp1 values (2,2001,700)
insert into #temp1 values (2,2002,1100)
insert into #temp1 values (2,2002,200)
insert into #temp1 values (2,2002,700)
insert into #temp1 values (2,2002,1100)
insert into #temp1 values (2,2003,200)
insert into #temp1 values (2,2003,700)
insert into #temp1 values (2,2003,1100)
insert into #temp1 values (3,2001,500)
insert into #temp1 values (3,2001,1500)
insert into #temp1 values (3,2001,1000)
insert into #temp1 values (3,2001,500)
insert into #temp1 values (3,2002,1500)
insert into #temp1 values (3,2002,1000)
insert into #temp1 values (3,2003,500)
insert into #temp1 values (3,2003,1500)
insert into #temp1 values (3,2003,1000)
-------------------------------------------------------------------------
select id,year1,sum(count1)
from #temp1
group by id,year1
with rollup

-----------------------------------------------------------------------------
WITH CUBE
select id,year1,sum(count1)
from #temp1
group by id,year1
with cube

-------------------------------------------------------------------------
select id,year1,sum(count1)
from #temp1
group by grouping sets((id,year1),())

--------------------------------------------------------------------------
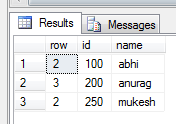
select
case when grouping(id)=0 then id
else 100 end as id,
year1,sum(count1)
from #temp1
group by grouping sets((id,year1),())

--------------------------------------------------------------
select id,
case when
grouping_id(id,year1)=0
then year1
when
grouping_id(id,year1)=1
then 100
when
grouping_id(id,year1)=3
then 300 end as year1,
sum(count1),
grouping(id) as grouping_id1,
grouping(year1)as grouping_year1,
grouping_id(id,year1) as grouping_id_column
from #temp1
group by id,year1
with rollup










![LOCKING HOW IT HAPPENS IN REAL TIME.[SP_WHO2]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEigZxH9ibJGOfSRALh4SFPVfwXffG4aJXa8S48STCUmsDvr0Q0TmOkUFiTR8djrOLLvZBZ3PSvgQGXS8W7JOeOU__MDcEF_Hq8A0_Hb7It_aHBctJ5KHAZSjcdUCD9DUkwtJZPll0HyCnb2/s72-c/11.PNG)

![HOW TO FIND Nth HIGHEST NUMBER THE COMMON INTERVIEW QUESTION. [OFFSET/FETCH USE TO FIND THE SAME]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhwH2YIGCemIzMO467RzSpbE8dL2J9lPMFMUrkD7E2rzkDkiIEXPOzF98lJA9pdR3uMydxI7EUgro7xEG5TfLwSO4BbGunLplVsrBrL7pUGOjkaJ2ZUybINsZQK9n3MYFYPIatxAMW8vaQN/s72-c/1.PNG)
