
create table #duplicaterows
(
id int,
name varchar(50)
)
go
insert into #duplicaterows
select 200,'anurag'
union all select 200,'anurag'
union all select 200,'anurag'
union all select 100,'abhi'
union all select 100,'abhi'
union all select 250,'mukesh'
union all select 250,'mukesh'
go
select * from #duplicaterows

-->how to get the distinct rows from table
-------------
select *
from #duplicaterows
-------------
;with cte(row,id,name)
as
(
select row_number() over(order by id) as row,* from #duplicaterows
)
select * from cte c1
where c1.row =
(
select max(c2.row) from cte c2
where c2.id=c1.id and c1.name=c2.name
)
O/P:

the best way to understand the above query is
1)first thing we don't have identity column. Use cte and create row number for the table.
2)Then correlated query. [imagine both tables as below]. Now both tables are created as c1 and c2
3)now we will selecting max row from cte(c1) [comparing with cte(c2) fetching maximum one]
--cte c1

--cte c2
--Fetching 2,5,7 (the max one)
so output is :
------------Trick 2: ------------------------------------
;with cte(row,id,name)
as
(
select row_number() over(partition by id order by id) as row,* from #duplicaterows
)
select * from cte c1
where c1.row =
(
select max(c2.row) from cte c2
where c2.id=c1.id and c1.name=c2.name
)
o/p
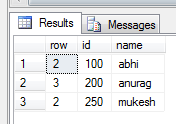
Lets understand this
1)after partition
;with cte(row,id,name)
as
(
select row_number() over(partition by id order by id) as row,* from #duplicaterows
)
select * from cte c1

as
(
select row_number() over(partition by id order by id) as row,* from #duplicaterows
)
select * from cte c1
2)selecting the max row individually for the matching id using corrleated query(the inner query).
where c1.row =
(
select max(c2.row) from cte c2
where c2.id=c1.id and c1.name=c2.name
)
-----------------------------------------------------Deleting----------------------------------------------------
Trick 1:
So the main table is :
;with cte(row,id,name)
as
(
select row_number() over(order by id) as row,* from #duplicaterows
)
select * from cte c1
So if we can delete the the id -->2, id-->(3,4), id (6). Then we can delete the duplicate rows.
In the inner query where we get the max. So if outer query is less than that max ==> delete.
Means for example
: : three anurag is there.
Delete anurag from the base table
(outer query) whose id is < (inner query) the max id of anurag[5].
so 3 and 4 will be deleted.
The final query will be like this :
;with cte(row,id,name)
as
(
select row_number() over(order by id) as row,* from #duplicaterows
)
delete from cte
where row <
(
select max(c2.row) from cte c2
where c2.id= cte.id and cte.name=c2.name
)
select * from #duplicaterows

Trick 2:
;with cte(row,id,name)
as
(
select row_number() over(partition by id order by id) as row,* from #duplicaterows
)
delete from cte where row >1
--Kindly give feedback if it helped you.


No comments:
Post a Comment